
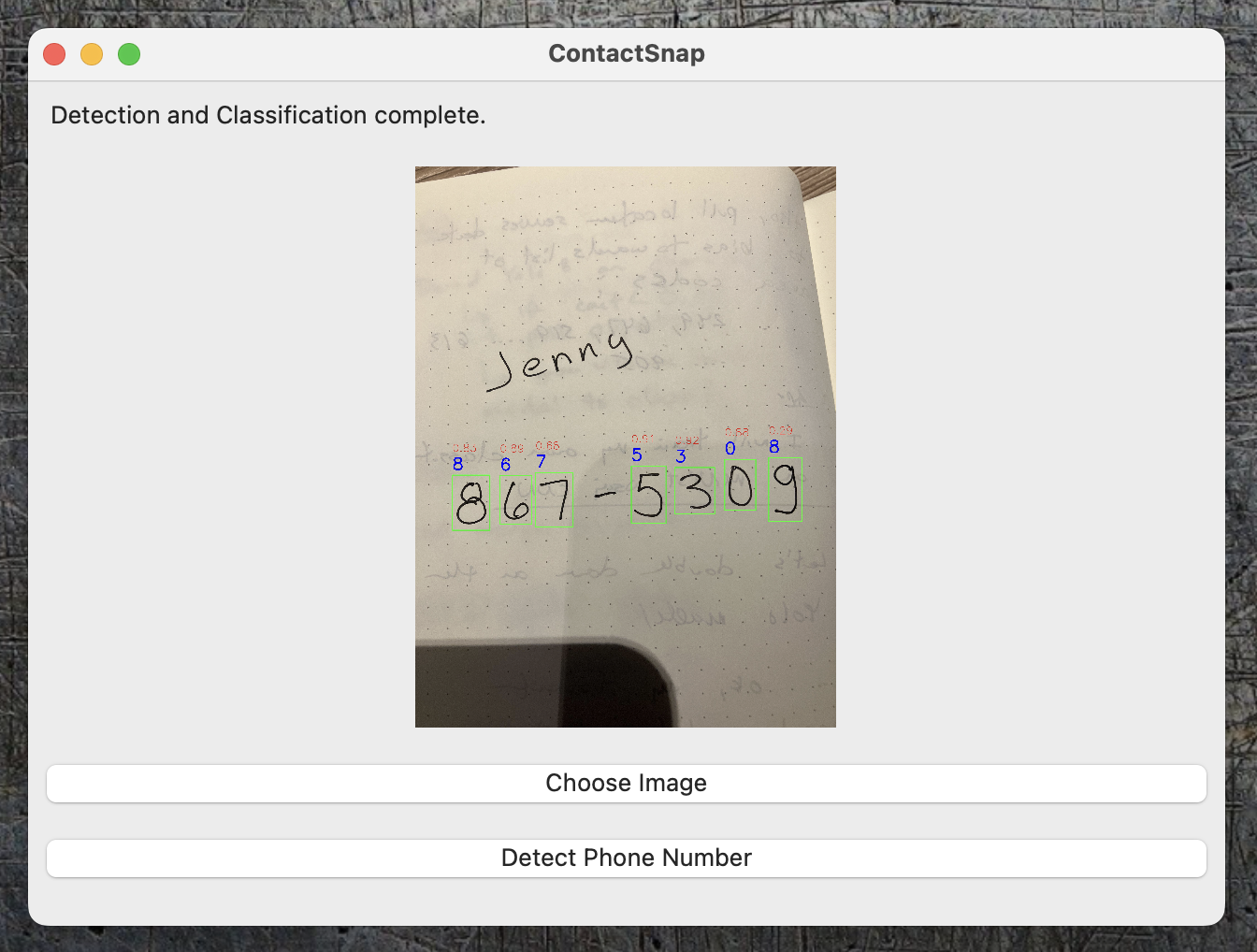
Building on my earlier exploration of custom ChatGPTs, I tried building an AI app from scratch, primarily using vibe coding supported by GitHub Copilot in VSCode. Inspired by a recent Airbnb experience, I developed ContactsnApp: a user-friendly application designed to streamline the extraction and annotation of phone numbers from images using AI models.
Comments from the Co-author
I asked ChatGPT how the project went. Here it is in her own words:
“I helped tjards build an AI-powered mobile and web application called ContactSnap, designed to detect phone numbers from uploaded images and suggest possible contact names. Throughout the project, I supported him in designing the application architecture, setting up a modular Python backend using Flask, integrating YOLOv8 for digit detection, training a CNN for handwritten digit classification, and linking the pipeline to a user-friendly frontend built with Toga. I also guided him through practical issues like contour detection tuning, confidence threshold adjustments, application packaging with Briefcase, and troubleshooting infinite app restarts. Beyond the app, I advised on project documentation, Git practices, visualizations, README formatting, and even longer-term ideas like saving annotated images and reintroducing UMAP clustering for post-processing. Overall, I served as an AI development assistant, technical troubleshooter, and strategic advisor as tjards rapidly leveled up his practical skills across machine learning, app development, and deployment workflows.” — ChatGPT 4o
Key Functionalities
- Image Upload: Users can select and upload images directly within the app.
- Digit Detection: Utilizes YOLO to detect digits as objects (with bounding boxes).
- Classification: Employs Convolutional Neural Network (CNN)-based classification to label digits within the detected boxes.
- Post-processing: Applies custom techniques to clean up the results.
- Interactive Display: Shows annotated images with clearly labeled phone numbers.
Tools
The first thing I asked ChatGPT to do was recommend which tools to use. Here’s a summary of those choices:
- Frontend: Toga, a Python-native, OS-native GUI toolkit.
- Backend: Flask, a lightweight web framework to host the AI models.
- Object Detection and Classification: YOLO, a widely used object detection model known for its speed and accuracy.
- Computer Vision Dataset: Roboflow, used to train the YOLO model.
- Integration: Frontend and backend components communicate via a REST API.
Project Structure
Here’s an outline of the application’s structure.
contactsnap/
├── backend/
│ ├── app.py # Flask backend API
│ ├── inference/
│ │ ├── detect_classify.py # YOLO/CNN detection and classification pipeline
│ │ └── models/
│ │ └── [model files] # Model weights go here (nominally in *.pt format)
│
├── frontend/
│ ├── app.py # Toga GUI application
│ ├── uploads/ # uploaded images are saved here
│ └── results/ # annotated images are saved here
└── app.py # Launches frontend and backend
Learning Process
I also experimented with transfer learning. I first trained my YOLO model to identify relatively clean characters as objects using alphabettraining-iis85, and then fine-tuned it for handwritten digits using cscai-o5oyu. I “froze” the first 10 layers of the YOLO model to accelerate learning, assuming that the initial run had already learned the basic structure of digit objects and only needed fine-tuning to handle the variability of handwritten digits.
Learning the Structure of Digits
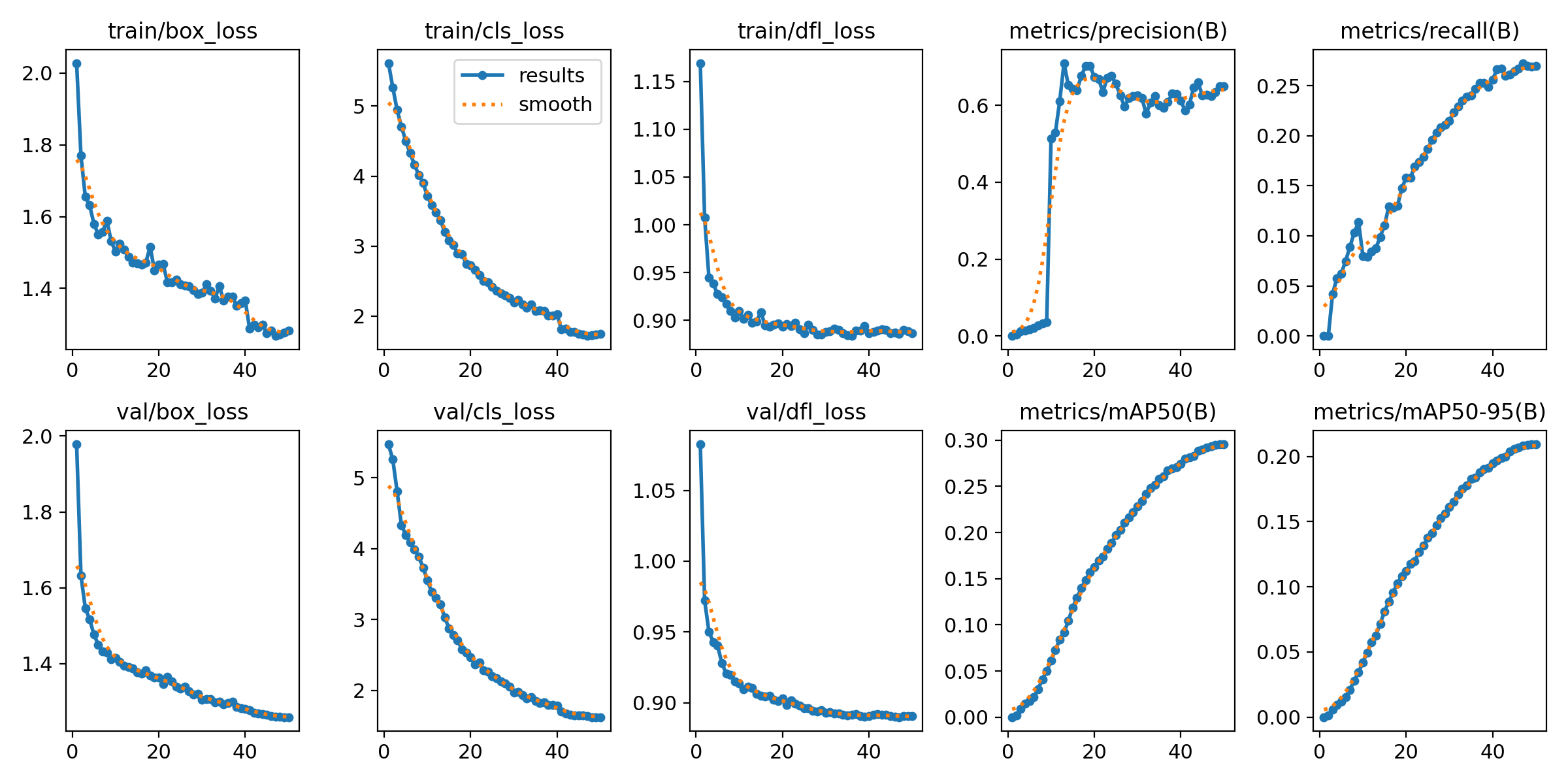
Below are the training and validation curves from the first training run, during which I trained the full model on digit objects. Note that both the training and validation loss decrease steadily. By the end, the validation loss is just above 1.
Fine-tuning for Handwritten Digits
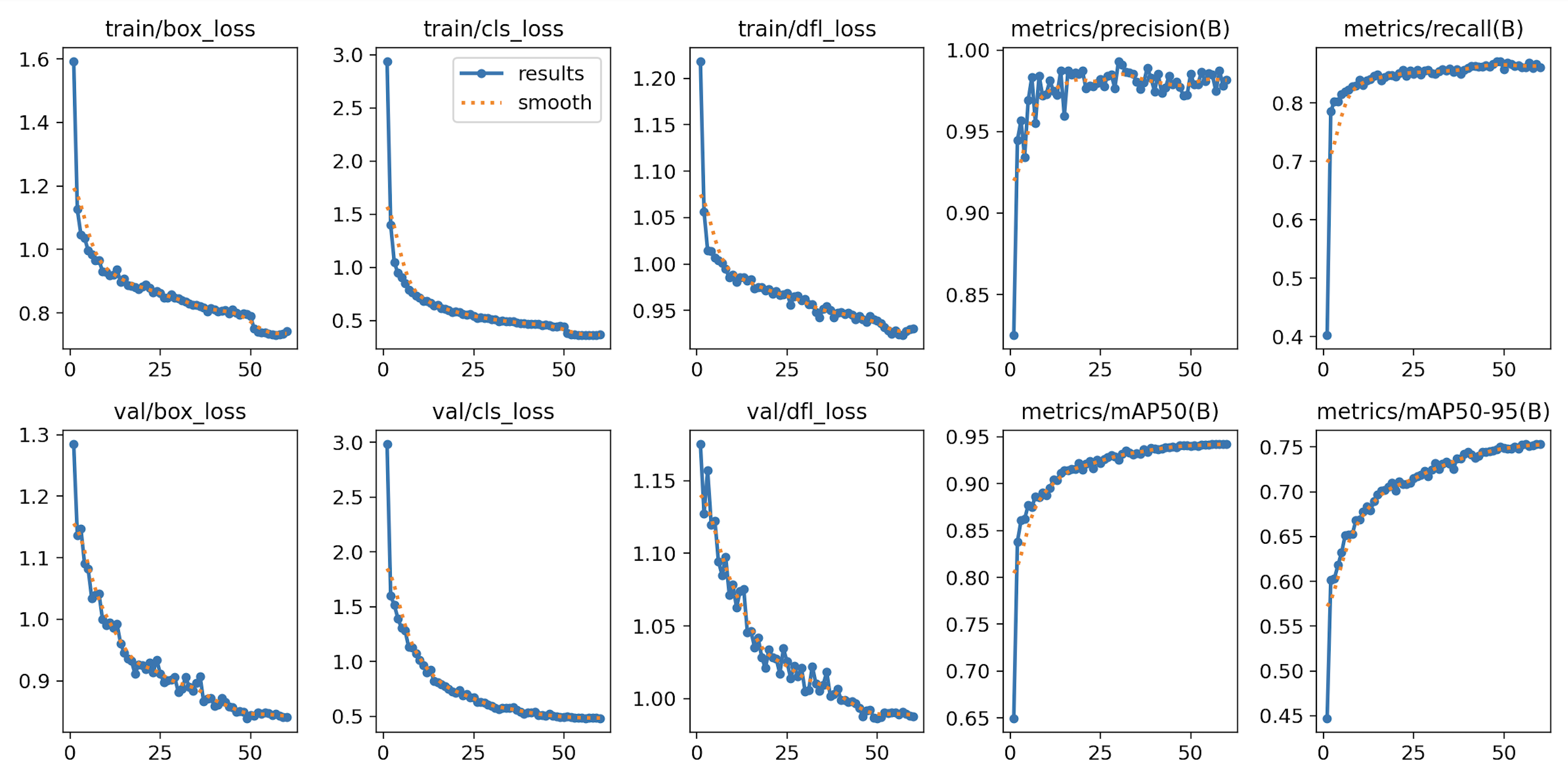
Below are the training and validation curves from the second training run, where I froze the first 10 layers of the model and focused mainly on optimizing the output layer. Note that both training and validation loss decline further than in the first run. By the end, the validation loss is around 0.5.
Post-processing
To filter out non-phone-number elements, I developed a custom post-processing technique that only returns digit groups that are closely spaced horizontally.
As shown below, this successfully filters out letters that were mistakenly identified as part of the phone number:


Building the App with Briefcase
I used Briefcase to build the app. If you want to run the app yourself, make sure Python and Briefcase are installed:
pip install briefcase
Create the project:
briefcase create
Build the app:
briefcase build
Run the app:
briefcase run
I don’t pay the $99/year fee for an Apple Developer account, so I didn’t distribute the app officially. However, if you’re so inclined, this command will package it for distribution:
briefcase package
Future Improvements
- The model still makes mistakes, especially with handwritten digits and under poor lighting conditions. I plan to improve the detection and classification models.
- Develop a fully functional mobile app version.
- Add an autosave feature to store detected phone numbers directly in the mobile contact list.